インテル謹製の数値演算ライブラリ「MKL」を使ってプログラムを高速化
各種スケジューリング処理やシミュレーション、統計処理、デジタル制御や信号処理などの分野では、多次元行列演算や高速フーリエ変換(FFT)、線形計画法など、さまざまな数学的処理が必要とされる。これらの処理に対するアルゴリズムはほぼ完成されており、フリー/商用を問わず、すでに多数の計算ライブラリがリリースされている。その1つが、インテルが提供する「インテル マス・カーネル・ライブラリ」(Intel Math Karnel Library、以下MKL)だ。
MKLはインテル コンパイラーに標準で付属している数値演算ライブラリで、同社のItaniumやXeon、Pentium 4、Core 2、Core i7といったCPUで高速に動作するよう最適化されているだけでなく、マルチプロセッサー/マルチコアCPU環境での並列処理に対応しているのが特徴だ。
本記事では、このMKLが備えている機能を紹介するとともに、フリーのライブラリと比べてどの程度の性能差があるのか、検証を行っていく。
MKLの構成と含まれる数値演算ライブラリ
まずはMKLについて簡単に紹介しておこう。MKLは、次のような特徴を備えた数値計算ライブラリだ。
○多数の数値演算関数を搭載MKLは、下記のような数値演算関数を搭載している。
- BLAS(行列/ベクトル演算)
- スパースBLAS(疎行列/疎ベクトル演算)
- LAPACK(多次元線形方程式処理)
- ScaLAPACK(多次元線形方程式処理)
- スパースソルバー
- ベクトル演算
- ベクトル統計
- 高速フーリエ変換 (FFT)
- クラスターFFT
- 区間ソルバー
- 三角変換
- ポアソンソルバー、ラプラスソルバー、およびヘルムホルツソルバー
- 最適化ソルバー
これらは制御/計測/シミュレーション/信号処理/統計処理などで多く使われる数値演算関数で、すべて倍精度の浮動小数点演算に対応している。
○マルチプラットフォームWindowsおよびLinux、Mac OS X版が用意されており、それぞれWindows版/Linux版/Mac OS X版のインテル コンパイラー プロフェッショナルエディションに付属している。どのプラットフォームでも同じ関数/APIが提供されており、プラットフォームを意識せずに利用が可能だ。
○CおよびFortranの両方から使用可能MKLにはCおよびFortran用のインターフェイスが用意されており、どちらの環境からも利用できる。
○32ビットおよび64ビットの両環境に対応MKLはx86、x64、IA-64(Itanium)の3つのアーキテクチャに対応しており、それぞれのアーキテクチャ用ライブラリが付属している(Mac OS X版はx86とx64のみ)。
○スタティックリンクとダイナミックリンクの両方でリンク可能すべてのアーキテクチャにおいてスタティックリンク版とダイナミックリンク版の両方のライブラリが用意されている。
○マルチスレッド対応/並列化対応MKLすべての関数はマルチスレッド環境でも安全に動作する(スレッドセーフ)ほか、簡単な指定でライブラリをマルチスレッド動作させ、並列処理を行わせることも可能だ。
○MKLを使用するアプリケーションの再配布は無償MKLを使用したアプリケーションを再配布は、本数の制限なく無償で行える。
MKLを採用するメリット
MKLで扱われている数値計算処理のほとんどは、その解法アルゴリズムが確立しているものであるため、すでにオープンソースのライブラリが提供されていたり、また文献を参照して自分で実装することも可能である。では、MKLのメリットはどこにあるのかというと、まず1つにその演算速度が挙げられる。
MKLはインテル コンパイラーと同様、各種インテル製CPUに最適化してコンパイルされており、高速な動作が期待できる。また、実行環境から自動的にCPUを判断し、もっとも最適なルーチンを選択するため、さまざまなCPUで高速に動作する。一方、オープンソースのライブラリの場合、配布されているバイナリは汎用CPU用のものが多いため、特定の環境向けにチューンアップするには自分でオプションを設定してコンパイルする必要がある。また、このようなオープンソースのライブラリはLinux/UNIX環境で開発されているものが多く、Windows環境ではコンパイルできない、もしくはコンパイルにLinux/UNIXの知識が必要で手間がかかる場合も多い。このような「無駄な手間」をかけずに、すぐに高速なライブラリが利用できるメリットは大きいだろう。
また、マルチスレッド動作に対応し、簡単な設定で処理を並列化できるというメリットもある。最近はマルチプロセッサ/マルチコア構成のPCも増えているが、並列化に対応している数値演算ライブラリは多くない。MKLの場合、同時処理できるスレッド数に応じて自動的に処理を並列化できるため、マルチプロセッサ/マルチコアのパフォーマンスを最大限に利用できる。
そして、MKLを使用したプログラムの配布が、有償/無償や配布数に関わらずすべて無償で行えるというのも、商用製品を開発する開発者にとっては見逃せない。オープンソースのライブラリはGPLなどで配布されていることが多いが、このようなライセンスは企業内では利用できないことも多いだろう。そういった場合、MKLは有用な選択肢の1つとなる。
MKLのパフォーマンスを調べる – 行列演算
では、広く普及しているフリーのライブラリと、MKLのパフォーマンスの差はどの程度なのだろうか。まずは工学分野から金融分野まで広く使われている、行列演算のパフォーマンスを調査してみよう。
広く普及している行列演算ライブラリとしては、「BLAS」および「LAPACK」と呼ばれるものがある。BLASは、ベクトルと行列に対する基本的な線形代数演算(四則演算)を行うもので、Netlibプロジェクト(http://www.netlib.org/)によってFortranのソースコードおよびCインターフェイスが公開されているほか、各種スーパーコンピューターやUNIX向けの実装や、環境に合わせた最適化済みライブラリを作成する「ATLAS」(http://math-atlas.sourceforge.net/)という実装もある。また、LAPACKはBLASを利用した線形方程式ソルバーである。
MKLにはこのBLASと互換性のある行列演算関数を備えているので、まずはMKLに含まれるBLASと、Netlib版BLASおよびATLASについて、そのパフォーマンスを比較してみよう。
○MKLのBLASを使ってプログラムを書くMKLを使ったプログラムを書くのには、特に難しい点はない。通常のライブラリを使用する際と同じく、使用する関数を選択して対応するヘッダーファイルをインクルードし、適切なライブラリをリンクするだけである。Windows環境の場合、MKLのマニュアルはデフォルトでは「C:\Program Files\Intel\Compiler\11.0\066\cpp\Documentation\mkl」にインストールされる。PDF形式のリファレンスマニュアルについては日本語版が付属している(図1)ほか、エクセルソフトのWebサイトで日本語のインストールガイドや入門ガイドといったドキュメントが公開されている。
また、MKLのヘッダファイル類は「C:\Program Files\Intel\Compiler\11.0\066\cpp\mkl\include」以下に、ライブラリは「C:\Program Files\Intel\Compiler\11.0\066\cpp\mkl\ia32\lib」(x86環境の場合)にインストールされる。Visual Studioを使用する場合、プロジェクト設定で「追加のインクルード・ディレクトリー」および「追加のライブラリー・ディレクトリー」にこれらを加えておく。さらに、「追加の依存ファイル」でMKLのライブラリ本体を指定する。通常は「mkl_intel_c.lib」および「mkl_intel_thread.lib」、「mkl_core.lib」、「libguide40.lib」の4つを指定すれば良い(表1)。
| ライブラリ名 | 説明 |
|---|---|
| mkl_core.lib | MKLのコアライブラリ |
| mkl_intel_c.lib | cdeclインターフェイスライブラリ |
| mkl_intel_thread.lib | MKLが内部的に使用するスレッドライブラリ |
| libguide40.lib | MKLが内部的に使用する動的スレッド処理ライブラリ |
なお、Netlib版BLASおよびATLASはMKLに含まれるBLASとまったく同一のインターフェイスを持つため、ソースコードについてはそのまま流用し、使用するヘッダーファイルとライブラリを変えて再コンパイルして、それぞれのライブラリを使用する実行ファイルを作成した。コンパイラにはすべてインテル C++ コンパイラーを使用している。
また、Netlib版BLASおよびATLASはそれぞれソースコードでの配布となるため、それぞれが推奨しているGCCでコンパイルを行ってライブラリを作成した。
テスト結果はMKLが圧倒的なパフォーマンスを見せる
今回使用したテストプログラムは500×500の行列同士の乗算を100回繰り返すというもので、clock()関数を用いてプログラム実行直後と終了直前の時刻を取得し、その経過時間を測定した(リスト1)。ここで使われている「cblas_dgemm」という関数がBLASの行列乗算関数である。なお、GCC 4でのBLASのコンパイルでは「-O3 -march=core2」という最適化オプションを設定している。また、テスト環境には表2のようなCore 2 Duoマシンを使用した。
リスト1 サンプルプログラム(行列演算分のみ抜粋)
void prod_matrix_with_blas( double* matrixA, double* matrixB, double* matrixC, int dim ) {
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
dim, dim, dim, 1.0,
matrixB, dim,
matrixC, dim, 0.0, matrixA, dim);
}
※サンプルプログラム全文はこちら
| 項目 | スペック |
|---|---|
| OS | Windows Vista Businness SP1 |
| CPU | Core 2 Duo E6550(2.33GHz) |
| メモリ | 2048MB |
さて、テスト結果であるが、次の表3のような結果となった。MKLを使ったプログラムは処理時間がATLASのほぼ半分と、非常に高いパフォーマンスを発揮している。
| ライブラリ | 1回目 | 2回目 | 3回目 | 平均 |
|---|---|---|---|---|
| MKL | 1.872秒 | 1.95秒 | 1.887秒 | 1.903秒 |
| ATLAS | 3.9秒 | 3.9秒 | 3.884秒 | 3.895秒 |
| BLAS | 16.13秒 | 16.099秒 | 16.13秒 | 16.120秒 |
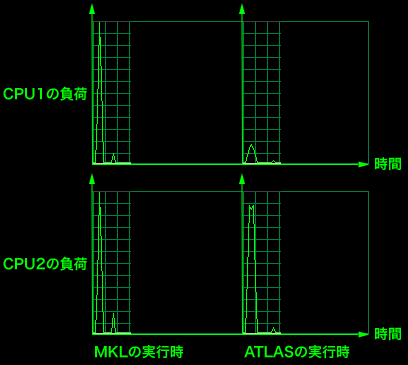
また、それぞれのプログラムを実行した際のCPU負荷を見てみると、MKLを使ったプログラムを実行した際はCPUの2つのコア両方に負荷がかかっているのに対し、ATLASを使ったプログラムは片方のコアに負荷が集中しているのが分かる(図2)。つまり、MKLは処理を並列化して2つのコアで同時に処理するため、片方のコアしか使っていないATLASと比べてほぼ半分の時間で処理を完了できていると推測できる。
MKLのパフォーマンスを調べる – 高速フーリエ変換
続いて、高速フーリエ変換(FFT)のパフォーマンスを確認してみよう。FFTは信号処理や画像/音声処理などの分野で多く用いられている処理で、データの周波数特性を分析するために使われる解析処理である。FFTを実装したフリーのライブラリとしては、GPLで提供されているFFTWがある。ここではその最新版であるFFTW Version 3.2と、MKLのフーリエ変換ライブラリを比較してみよう。
FFTWは、マサチューセッツ工科大学(MIT)のMatteo Frigo氏とSteven G. Johnson氏によって開発されたライブラリで、各種Linux/UNIXおよびWindowsで利用できる。CPUが備えるSSEやSSE2、3dNow!、Altivecなどの数値演算機能を利用した高速な演算が可能なほか、任意サイズのデータに対してフーリエ変換/逆フーリエ変換の両方が行えるといった特徴を持ち、各種数値計算ツールなどでも多く採用されている。
MKLに含まれるFFT関数はFFTWとの互換性はないものの、FFTWと同様のインターフェイスを持つラッパーライブラリのソースコードが付属しており、これを利用することでFFTWを簡単にMKLに置き換えることができる。今回はこのラッパーライブラリを使用してFFTWで行っていたプログラムのFFT処理部分をMKLに置き換え、処理時間がどのくらい変わるのか調べてみよう。
なお、このラッパーライブラリはデフォルトでは「C:\Program Files\Intel\Compiler\11.0\066\cpp\mkl\interfaces\fftw3xc」ディレクトリにインストールされるのだが、ソースコードのみしか含まれていないため、ライブラリを利用するためにはコマンドラインでnmakeコマンドを実行してコンパイルする必要がある。Windows環境の場合、スタートメニューの「Intel Software Development Tools」内にある「IA-32 対応アプリケーション用 C++ ビルド環境」を実行してコマンドプロンプトを開き、下記のように実行すればよい。
> cd C:\Program Files\Intel\Compiler\11.0\066\cpp\mkl\interfaces\fftw3xc > nmake lib32
これにより「C:\Program Files\Intel\Compiler\11.0\066\cpp\mkl\ia32\lib\」ディレクトリ以下に「fftw3xc_intel.lib」というライブラリが作成される。あとは「C:\Program Files\Intel\Compiler\11.0\066\cpp\mkl\include\fftw」以下にある「fftw3.h」をC/C++ソースコード内でインクルードし、上記で作成したfftw3xc_intel.libと、MKLのライブラリ「mkl_intel_c.lib」および「mkl_intel_thread.lib」、「mkl_core.lib」、「libguide40.lib」をリンクすれば、FFTWを利用するプログラムをそのままMKLを使って動かすことができる。
FFTWとMKLの処理速度を比較する
処理速度比較に使用するプログラムは指定したモノクロ画像に対して2次元のFFT処理を行うもので、幅3072ドット、高さ2304ドットの画像をFFT処理し、処理にかかった時間を測定するものだ(リスト2)。
リスト2 サンプルコードのFFT処理部分(抜粋)
/* 作業用メモリを割り当て */
in = fftw_malloc(sizeof(fftw_complex) * width * height);
out = fftw_malloc(sizeof(fftw_complex) * width * height);
/* データを作業用メモリにコピー */
for( n = 0; n < width*height; n++ ) {
in[n][0] = (float)input_image_buf[n];
in[n][1] = 0.0;
}
/* FFTエンジンを初期化 */
p = fftw_plan_dft_2d(height, width, in, out, FFTW_FORWARD, FFTW_ESTIMATE);
/* FFTを実行 */
fftw_execute(p);
※サンプルプログラム全文はこちら
なお、FFTWはWindows環境でもコンパイルできるが、GCC向けに最適化を行っているために他のコンパイラではコンパイルできなかったり、パフォーマンスが落ちるという問題があるようだ。そのため、今回はFFTWのWebサイトで配布されているバイナリ版DLLを使用した。
テストでは、FFTWを使ったプログラムをGCC 4およびVisual C++ 2008でコンパイルしたものと、MKLを用いたプログラムをインテル C++ コンパイラーでコンパイルしたものを用い、それらの処理時間を比較した。それぞれのコンパイルはコマンドラインで下記のように行った。
GCCでのコンパイル: > gcc-4.exe -L. -o fft1_gcc.exe -lfftw3-3 -lm -O3 -march=core2 fft1.c Visual C++でのコンパイル: > cl.exe /Ox /Oi /Ot libfftw3-3.lib /Fefft1_vc.exe fft1.c
さて、それぞれの実行時間をまとめたものが表4である。MKLを使用したプログラムは、FFTWを使ったものと比べて約60%高速に動作するという結果となった。
| プログラム | 1回目 | 2回目 | 3回目 | 平均 |
|---|---|---|---|---|
| GCC 4 + FFTW | 1.576秒 | 1.513秒 | 1.513秒 | 1.534秒 |
| Visual C++ + FFTW | 1.326秒 | 1.279秒 | 1.263秒 | 1.289秒 |
| インテル C++ コンパイラー +MKL | 0.733秒 | 0.873秒 | 0.780秒 | 0.795秒 |
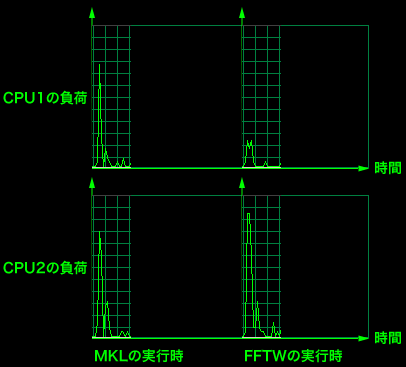
FFT処理についても先のBLASの例と同様、複数のCPUコアを使って並列処理を行うことで、高速な処理を実現しているようだ(図2)。
特にマルチプロセッサ/マルチコア環境でパフォーマンスを発揮
今回MKLとの比較に使用したBLASやFFTWといったライブラリは、比較的定番のライブラリであり、実際に使っているユーザーも多いだろう。このようなライブラリをMKLに置き換えるだけで、プログラムの高速化が期待できる。特にマルチプロセッサ環境では、並列化により大幅なパフォーマンス向上が期待できる。
また、BLASやFFTWといったオープンソースのライブラリは、それらを利用して作成したバイナリを配布することを考えると使いにくいこともある。マルチCPU/マルチコア環境のパフォーマンスを最大限に活用したい場合や、Windows向けの業務向け/商用アプリケーションの開発を行う場合などに、MKLはぜひ検討したい数値演算ライブラリと言える。