パフォーマンス解析ツール「VTune」でアプリケーションを高速化
作成したプログラムのパフォーマンスに問題がある場合、性能解析ツールを利用して問題点を分析するのが一般的だ。性能解析ツールには様々なものがあるが、その中でも高機能なものとしてインテルが開発する性能解析ツール「インテル VTune パフォーマンス・アナライザー」がある。
本記事ではパフォーマンスの問題が発見されたプログラムを対象に、このインテル VTune パフォーマンス・アナライザーを使用して問題点の調査とパフォーマンスの改善を行う例を紹介する。
パフォーマンスが低下する原因を特定するツール「プロファイラ」
作成したプログラムの性能解析を行うツールとして、たとえばVisual Studioには「Visual Studio プロファイラ」というプロファイラが搭載されているほか、GCCではgprofというツールを利用できる。このようなプロファイラを利用することで、プログラム中のどの関数が何回呼ばれているのか、またその関数の実行時間はどれくらいか、といった統計情報を収集することが可能だ。
インテルの「インテル VTune パフォーマンス・アナライザー」(以下、VTune)は、このようなプロファイラ製品の1つである(図1)。プロファイラ製品は先に挙げたVisual Studio プロファイラやgrpof以外にもさまざまなものがあるが、VTuneが他の製品と一線を画すのは、パフォーマンスを解析したいプログラムだけでなく、プログラム実行時のシステム全体の状況をサンプリングできる、という点だろう。
インテルの製品紹介ページで公開されている「Advantages Of VTune Performance Analyzer Over Other Profilers」(PDF)と題した資料によると、VTuneは次のような特徴を備えている。
・オーバーヘッドが小さいVTuneは非常に低い負荷でアプリケーションの挙動をサンプリングできるため、サンプリングによる対象プログラムの動作への影響が少ない。そのため、プロファイラを実行していない通常の動作に近い挙動を測定できる。
・システム全体を分析できるマルチタスクOSの上では、アプリケーションは単独で動作しているわけではない。そのため、そのパフォーマンスは常にOSやドライバ、ほかのアプリケーションなどの影響を受けて変動することになる。VTuneはCPU上で実行されるすべての命令についてサンプリングを行うため、アプリケーション実行時のOSやそのほかのアプリケーションの挙動までも含めた分析を行える。
・ソースコードが不要VTuneで解析したいアプリケーションのソースコードがなくとも、プロファイリングが行える。たとえばVTuneには、プログラム中のどのような関数がどのように呼び出されたかを解析する「Call Graph」という機能があるが、ソースコードが無くてもどのような関数が呼び出されているのかを解析することが可能だ。もちろん、ソースコードがあればより詳細な情報を表示できる。
・コードの修正なしにサンプリングが可能たとえばGCCの場合、gprofでサンプリングを行う場合は「-pg」オプションを付けてコンパイルを行う必要があるが、VTuneではこのような特別なコンパイルオプションやライブラリへのリンク、ソースコードの修正などは不要だ。VTuneではデバッグ情報さえあればパフォーマンスのサンプリングが行える。
さらに、ソースコードとデバッグ情報の両方が利用できる環境の場合、CPUが備える動作統計情報取得機能を利用してソースコード中のどの部分でどのような問題が起きているのかを検出しチューニングの指標を示す機能など、より高度な機能をより効果的に使用できる。
ImageMagickのパフォーマンス低下の原因はどこ?
「インテル コンパイラーでオープンソースソフトウェアをコンパイルしよう」記事では、画像のバッチ処理ツール「ImageMagick」をインテル コンパイラーでコンパイルし、その性能を評価している。そこで興味深かったのが、インテル コンパイラーでコンパイルした場合に特定機能のパフォーマンスが低下する点だ。
詳細については先の記事を参照してほしいが、ImageMagickに含まれる「convert」コマンドで画像にblur(ぼかし)操作を行った場合に実行速度が低下するという問題が発見できた。そこで、この問題の原因はどこにあるのか、VTuneを使って調査してみよう。
VTuneのインストール
今回は、VTuneの国内代理店であるエクセルソフトのWebサイトからダウンロードできる体験版を利用して調査を行った。使用したのはWindows版VTune 9.1で、30日間の期限付きではあるが製品版のすべての機能が利用可能だ。体験版のダウンロードにはメールアドレス等の入力が必要だが、ここで登録したメールアドレス宛に体験版のシリアル番号およびライセンスファイルが送られてくるので、有効なメールアドレスを入力しよう。
ダウンロードしたVTune体験版のインストーラを実行するとインストールウィザードが表示されるので、指示に従ってインストールを行う。インストールにはシリアル番号、もしくはライセンスファイルの指定が求められるので、登録したメールアドレスに送られてきたシリアル番号を入力しよう(図2)。なお、シリアル番号での認証にはインターネット接続が必要なので、もしインターネット接続できない環境でインストールを行う場合は、メールに添付されているライセンスファイルを適当なフォルダに保存し、「Provide a license file」を選択してそのファイルを選択しよう。
また、VTuneにはVisual Studio 2005/2008からVTuneの機能を呼び出せる統合機能もあるが、Windows Vista環境ではVisual Studio 2005からVTuneのCounter Monitor機能を利用する場合にエラーが発生する場合がある。また、Visual Studio 2008との統合については対応していないので注意してほしい。インストーラのデフォルト設定では「Visual Studio 2008 integration」機能はインストールされないようになっているので、その設定のままインストールを進めよう(図3)。もしこちらをインストールしてしまうとVisual Studioの起動時にエラーが発生するようになってしまうので注意してほしい。
Call Graph機能でボトルネックとなる関数を調べる
まずはVTuneの「Call Graph」機能を使用し、ソースコード中のどの関数がボトルネックになっているのかを調査してみよう。Call Graph機能は関数単位でプログラムの挙動を調査するもので、次のような統計情報を取得できる。
- それぞれの関数が何回呼ばれているか
- それぞれの関数内がどれだけの時間実行されているか
- ある関数がどの関数を何回呼んでいるか
- ある関数がどの関数から何回呼ばれているか
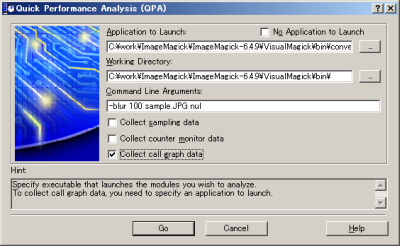
VTuneを起動するとまずは「Easy Start」画面が表示されるので、ここで「Quick Performance Analysis Wizard」を選択しよう(図4)。すると「Quick Performance Analysis(QPA)」画面が表示されるので、「Application to Launch:」で起動したいプログラムを指定する(図5)。また、プログラムに渡す引数は「Command Line Arguments:」で指定できる。今回はCall Graphでの解析を行うので「Collect call graph data」にチェックを入れ、「Go」をクリックすると指定したプログラムが起動され、調査が行われる。
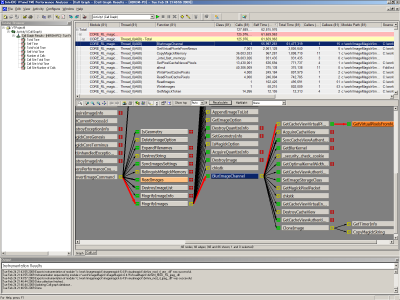
プログラムが終了すると、自動的にデータの収集と解析が行われ、画面の上ペインに呼び出された関数一覧が、下ペインに関数の呼び出し関係をグラフ化したCall Graphが表示される(図6)。
上ペインの関数一覧では、関数が含まれるモジュール(実行ファイルやDLLなど)、実行したスレッド、呼び出された回数などが関数名とともに一覧表示される。ここで「Calls」が呼び出された回数、「Total Time」はその関数が消費された時間を示している。ここで注目すべきなのが、「Self Time」項目である。このSelf Time項目は、ソースコード中でその関数内に記述されている処理がどれだけ時間を使っているか、ということを示すものだ。
たとえば今回の例の場合、「Self Time」項目を見ることでCORE_RL_magick_.dllというモジュール内の「BlurImageChannel」という関数が、プログラムが実行時間(実時間ではなく、CPUのサイクル単位で表示される点に注意)62,815,976単位のうち、55,997,261単位を占めているということが分かる。つまり、この関数が今回の処理の「ホットスポット」(プログラムの実行時間の大部分を占めるポイント)となっているわけだ。
さて、プログラムのパフォーマンスを改善するにはこのホットスポットを高速化すれば良いのだが、Call Graphでは「どの関数が時間を消費しているか」というのを調べることはできるものの、関数内のどのコードが問題なのか、またなぜ問題なのか、ということまでは分からない。そこで、続いてはプログラムの挙動を詳細に調べられるサンプリング機能を利用して、ソースコード中で問題となっている部分を特定してみよう。
サンプリング機能を利用して問題個所と解決策を探る
VTuneのサンプリング機能は、プログラム実行時におけるCPUの挙動をサンプリングすることで、プログラムの挙動や発生している問題を調査するものだ。なお、サンプリング機能はCall Graph機能と同様にデバッグ情報がないプログラムについても調査が可能だが、プログラムのデバッグ情報およびソースコードがあるとソースコードレベルでホットスポットを調査でき、より調査がしやすくなる。デバッグ情報は「/Zi」コンパイルオプションを付けてプログラムをコンパイルすることで生成できる(図7)。Visual Studioの場合、プロジェクトのプロパティ中「C/C++」の「全般」でデバッグ情報の形式が指定できるので、「デバッグ情報の形式」として「プログラム・データベース(/Zi)」を指定すれば良い。
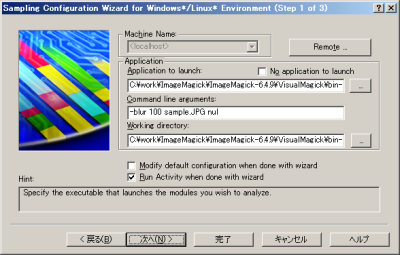
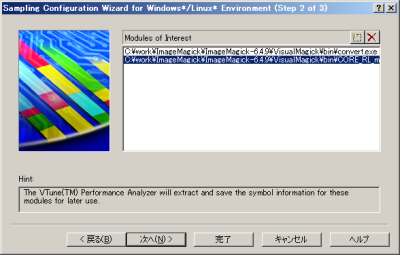
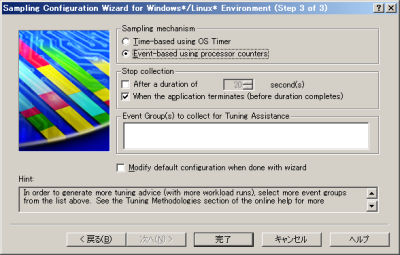
サンプリング機能の設定および実行は、「Sampling Configuration Wizard」を利用すると良い。ツールバーの「File」-「New Project」を選択すると「New Project」画面が表示されるので、「Sampling Wizard」を選択して「OK」をクリックしよう(図8)。すると「Sampling Configuration Wizard」が表示されるので、図9~12のように条件を設定し、サンプリングを実行する。
サンプリングの実行およびデータの収集・解析が完了すると、サンプリングされたプロセスが一覧表示されるとともに、「Intel Tuning Assistant」が表示される(図13、14)。Intel Tuning Assistantで表示されている「CPU_CLK_UNHALTED.CORE」はCPUが処理した動作サイクル数で、今回は143,365,224,000サンプルが収集された、ということを示している。
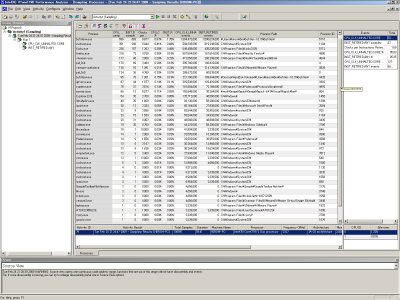
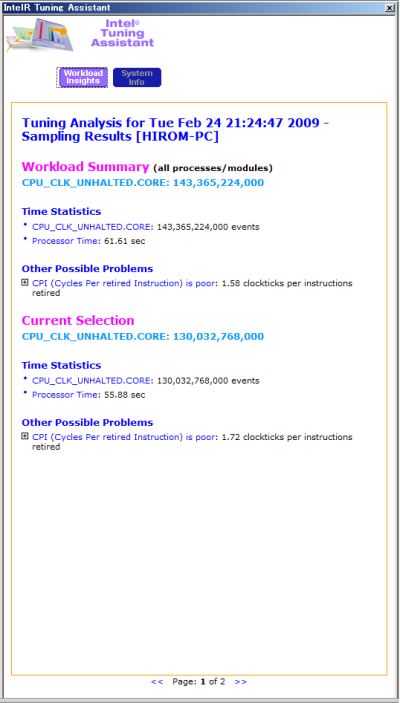
また、その下の「Other Possible Problem」ではパフォーマンス低下の原因と思われる項目が表示される。ここでは「CPI(Cycles Per retired Instruction)is poor」と表示されていた。その横には「1.58 clockticks per instructions retired」と表示があるが、この「clockticks per instructions retired」というのは、CPUがどれだけ「無駄な時間」を消費しているか、ということを表す指標だ。この値が大きいということは「キャッシュミス等が原因でCPUが処理を実行できない時間が多く存在した」ということを意味している。つまり、キャッシュミス等を改善すればアプリケーション全体のパフォーマンスを改善できる可能性がある、ということだ。そこで、続けてパフォーマンスが悪い個所の特定を行っていこう。
前述のとおり、VTuneではシステム全体に対してサンプリングを行うため、無関係なプロセスに関する情報も取得されている。ここで解析対象のプロセスをダブルクリックし、続けて対象スレッド、対象モジュールをダブルクリックで選択する(図15~ 図16)。
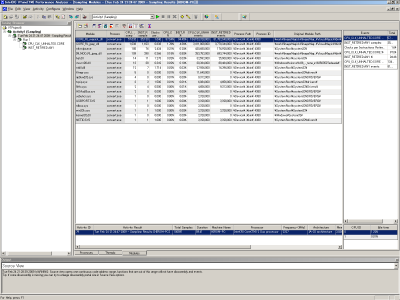
モジュール一覧画面で解析したいモジュールをダブルクリックすると、図17のような「Hotspots」画面となり、関数ごとにその関数が消費したCPUサイクル(CPU_CLK_UNHALTED.CORE)やCPUが実行できた処理の数(INST_RETIRED.ANY)といった情報が一覧表示される。ここで、「clockticks per instructions retired」の列を見てみると、「BlurImageChannel」という関数について「clockticks per instructions retired」の値が特に大きいことが分かる。
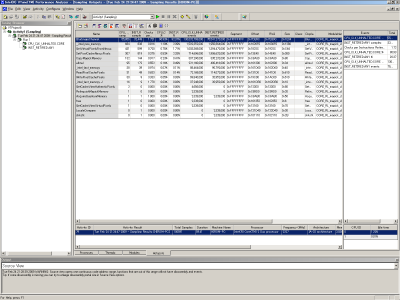
ここでさらに詳細を調べるために「BlurImageChannel」の列をダブルクリックしてみよう。すると、ソースコードとともにCPU_CLK_UNHALTED.COREやINST_RETIRED.ANYといったCPUの動作状況が表示される(図18)。ここから、「effect.c」中の964行以下の部分がCPUサイクルを多く消費していることが分かる。さらに、INST_RETIRED.ANYの値がCPU_CLK_UNHALTED.COREの値よりも大幅に小さいことから、CPUを効率的に利用できていない、ということも分かる。つまり、この部分がパフォーマンスのボトルネックとなっているということだ。
このボトルネックとなっていると思われる部分は次のような処理だ。これは非連続なメモリ領域に連続してアクセスする処理で、このような処理はキャッシュミスが発生しやすく、そのためにパフォーマンスが低下する原因となる。
for (i=0; i < (long) width; i++)
{
pixel.red+=(*k)*(p+i)->red;
pixel.green+=(*k)*(p+i)->green;
pixel.blue+=(*k)*(p+i)->blue;
k++;
}
それでは、この問題を解決するにはどうすればよいだろうか。問題は非連続なメモリ領域へのアクセスにあるので、これを連続したメモリ領域へのアクセスに修正すれば、よりCPUを効率よく利用できると考えられる。そこで、この処理を行う前に連続したメモリバッファを確保し、非連続なメモリ領域に格納されているデータをそこにコピーしてから乗算・加算処理を行うように修正した。修正後のソースコードは下記のようになる。
for (i=0; i < (long) width; i++ )
{
buf[i] = (p+i)->red;
}
for (i=0; i < (long) width; i++ )
{
pixel.red += (*(k+i)) * buf[i];
}
for (i=0; i < (long) width; i++ )
{
buf[i] = (p+i)->green;
}
for (i=0; i < (long) width; i++ )
{
pixel.green += (*(k+i)) * buf[i];
}
for (i=0; i < (long) width; i++ )
{
buf[i] = (p+i)->blue;
}
for (i=0; i < (long) width; i++ )
{
pixel.blue += (*(k+i)) * buf[i];
}
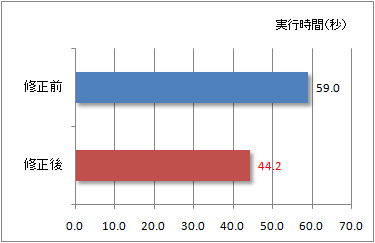
このように修正を加えたソースコードをインテル コンパイラーでコンパイルして変更前のバイナリと比較したところ、図19のような結果が得られた。修正前は59秒だった実行時間が修正後は44.2秒と、約3割もの高速化に成功している。
プログラム実行時の詳細なレポートでパフォーマンス改善
以上、簡単ながらVTuneの利用例を紹介してきたが、いかがだっただろうか。今回の例のような、キャッシュミス等によるCPUの動作パフォーマンス低下は、ソースコードだけからではどこがボトルネックなのかを判断するのは難しく、CPUの内部動作情報までも取得できるVTuneは性能解析に非常に有用である。
また、今回は使用しなかったが、VTuneではOSのコンテキストスイッチ数や空きメモリ容量の変化、ネットワークエラーの発生数といった統計情報を取得できる「Counter Monitor Collector」機能も備えている。これは、特定の条件で発生するような問題を解決する場合などに重宝する。
VTuneは「作成したプログラムのパフォーマンスを改善したいがどこに問題があるか分からない」といった場合などに役立つ、非常に心強いツールといえるだろう。